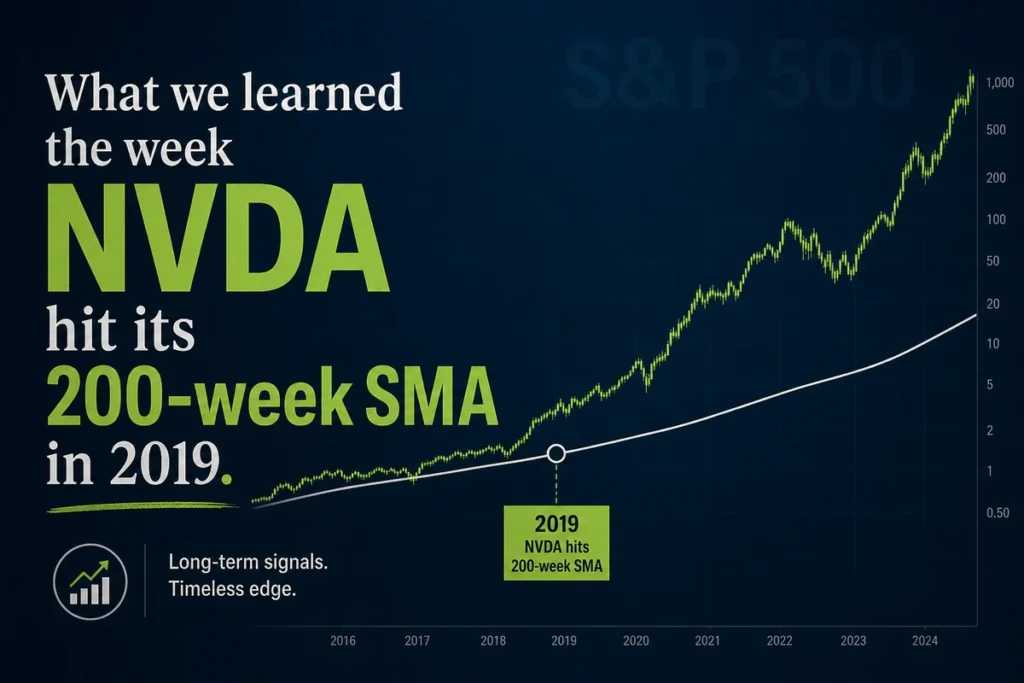
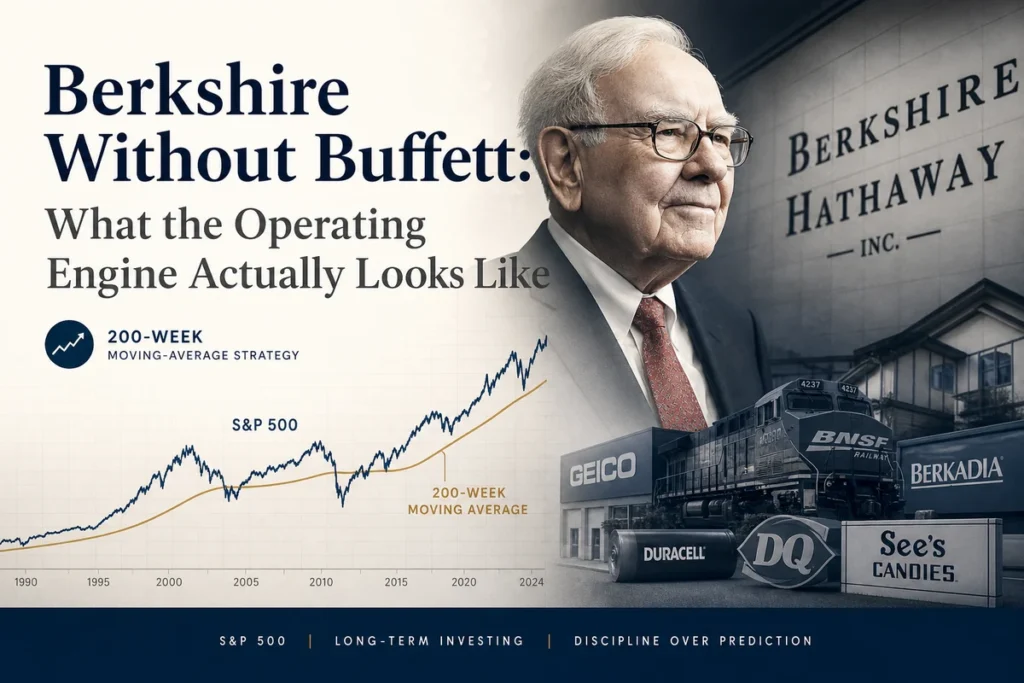
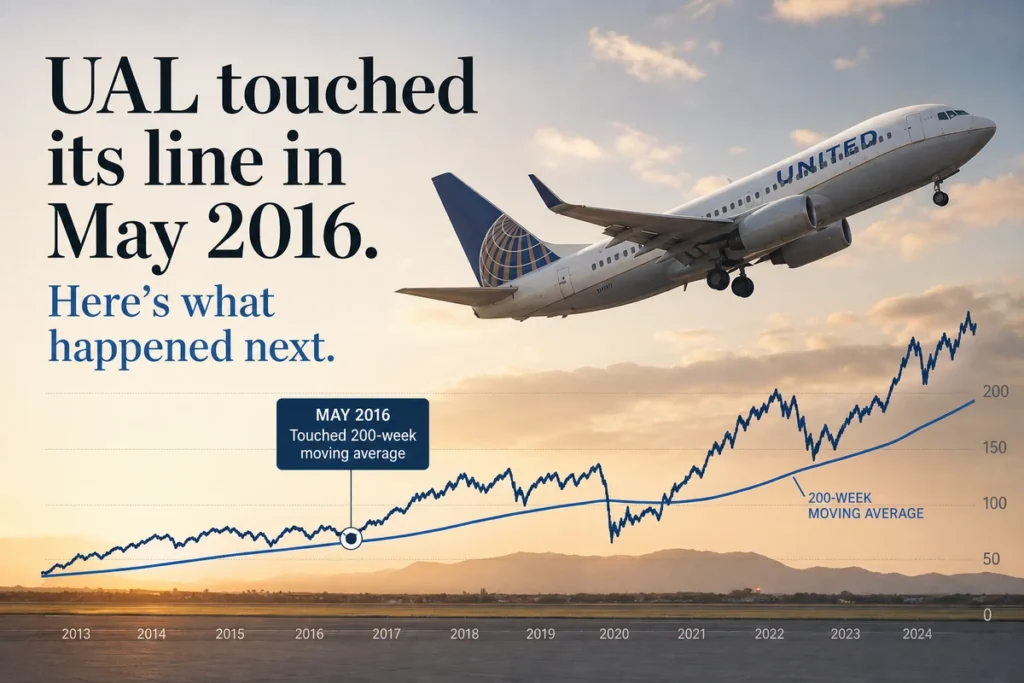
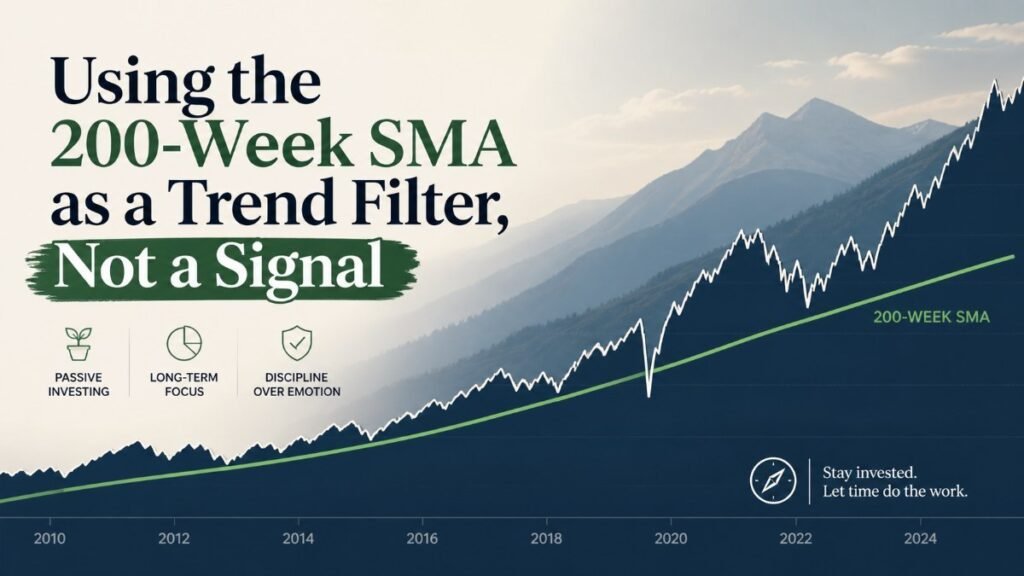
That distinction between in-sample fit and out-of-sample validity is the central issue in factor investing. McLean and Pontiff (2016) examined 97 published equity factor strategies and found that post-publication premiums fell by an average of roughly 32% compared to the figures reported in the original research. Part of that decay reflects arbitrage, capital flowing toward the known anomaly until it narrows. But part of it reflects the simpler truth that the in-sample result was never as strong as it appeared.
Value is the oldest and most studied premium. The idea, formalized by Fama and French’s HML factor (high book-to-market minus low book-to-market), is that cheap stocks, measured relative to their assets or earnings, tend to outperform expensive ones over long periods. The international evidence is reasonably consistent: a study of Canadian data from 1985 to 2005 found a persistent value premium that held across bull and bear markets, through recessions and recoveries, and survived when firm size was controlled for. Fama and French’s own international data showed an average value premium of approximately 7.68% annually from 1975 to 1995 across non-US developed markets. The mechanism has two competing explanations. One is rational risk compensation: value stocks tend to be distressed businesses carrying genuine operational risk, and investors require higher returns to hold them. The other is behavioral, rooted in investor overextrapolation of recent poor performance. Evidence suggests both forces are at work simultaneously, which is arguably why the premium has been durable despite widespread awareness.
The important caveat is that the value premium has been concentrated in small-cap stocks and in periods of economic stress. Asness and colleagues noted that there is no strong standalone value premium among large-cap stocks, and the premium in small-cap value has itself weakened in more recent decades. A value tilt in a large-cap-only portfolio may therefore be capturing far less than the historical record implies. The Shiller CAPE on the S&P 500 currently sits at 41.66, well above its long-run average, which suggests growth expectations remain elevated relative to value, and the conditions for a sharp mean reversion in factor spreads are present, though not guaranteed to resolve on any particular schedule.
Momentum may be the most empirically robust of all the major factors, which is precisely what makes it theoretically awkward. Stocks that have performed well over the prior six to twelve months tend to continue outperforming over the next one to twelve months. The effect has been documented across equity markets in the US, Europe, and emerging markets, in bond markets, in currencies, and in commodities. It persists in more recent data and shows limited evidence of the post-publication decay that afflicts weaker factors. Nearly ninety years after Cowles and Jones first documented serial correlation in stock returns, cross-sectional momentum remains a live anomaly. The challenge for theorists is that no clean risk-based story explains it. The Fama-French five-factor model deliberately excludes momentum for this reason. Behavioral explanations, particularly initial underreaction to new information followed by overreaction, fit the data reasonably well. For investors, the practical constraint is that momentum strategies carry high turnover, which generates meaningful transaction costs and potentially unfavorable tax consequences in taxable accounts.
Quality and profitability have accumulated strong evidence since Fama and French’s five-factor extension. Profitable firms, measured by operating profitability relative to book equity, consistently outperform unprofitable ones after controlling for size and value. The quality factor more broadly encompasses high profitability, low leverage, stable earnings, and strong cash flow generation. Crucially, profitability has a documented ability to improve the performance of value strategies: a cheap stock that is also profitable is historically superior to a cheap stock with deteriorating fundamentals. The combination reduces the “value trap” problem that afflicts naive cheap-stock screens. Profitability’s evidence is also credible because there is a plausible rational explanation, namely that genuinely good businesses deserve a premium, alongside a behavioral one, that investors systematically underestimate the persistence of high returns on capital.
Low volatility presents the most intellectually interesting challenge to standard finance theory. Portfolios of low-beta or low-volatility stocks have historically produced returns comparable to or exceeding the broader market, with less risk. This flatly contradicts the core prediction of the CAPM that more risk should mean more return. Research from AQR Capital Management on defensive equity demonstrated that high-beta stocks, despite receiving the majority of a typical portfolio’s risk budget, have historically returned approximately the same as low-beta stocks. Explanations range from structural constraints, such as leverage-averse institutional investors bidding up risky stocks to chase returns within a mandate, to pure mispricing by retail investors attracted to lottery-like payoffs. Whether the source is rational or behavioral, the anomaly has survived extensive out-of-sample testing across international markets and across decades.
Beyond these core factors, the picture deteriorates quickly. The size premium, the original Fama-French SMB factor, provides a useful case study. From 1926 through approximately 2006, the average SMB return was roughly 0.23% per month, and the premium was consistent across sub-periods. Since then, the evidence has weakened materially. Large-cap earnings multiples expanded so dramatically that the benchmark itself rose in ways that compressed the relative advantage of small stocks. Critically, broad small-cap indices mix genuinely undervalued businesses with structurally declining ones, meaning an undifferentiated small-cap tilt often captures beta exposure rather than any genuine premium. The size effect appears most alive in international markets and when explicitly combined with quality screens, but realistic forward expectations for a size tilt alone should be modest.
Below these established factors, the catalog of proposed anomalies spans accruals, asset growth, net operating assets, earnings quality, share issuance patterns, and dozens more. Many of these show impressive backtested returns and fade considerably after publication. The mechanism is not purely arbitrage. Data mining is a significant part of the explanation: a researcher running enough variables through enough historical periods will inevitably find patterns that are statistical accidents. Arnott and Harvey’s 2019 work argued directly that the statistical threshold for claiming a genuine factor should be substantially higher than the conventional significance levels that academic journals typically require, precisely because so many specifications are being tested on the same underlying data.
The problem with the factor zoo is not just that many entries are spurious. It is that even genuine factors can be exploited in ways that destroy most of their value. A factor that earns a meaningful annual premium in a clean academic long-short portfolio may deliver near-zero net alpha when implemented through a long-only ETF, after fees, taxes, and timing risk are accounted for.
Academic factor premia are almost always reported gross of costs, in idealized long-short portfolios that no retail investor can implement, and based on historical periods that may include regimes that no longer apply. Converting that theoretical premium into actual investor returns requires clearing several hurdles simultaneously.